For this project, my team and I attempted to classify the “mood” of song lyrics with a Convolutional Neural Network. We achieved a classification accuracy of 77%. Other published research works with heavily engineered SVM models scored less than 70%.
FYI - this page is a work-in-progress
Motivation
This project was completed as part of UC Berkeley’s Masters of Information and Data Science (MIDS) program in the course “W266 Natural Language Processing with Deep Learning”. It was done in the Fall semester of 2018.
We were tasked with conceptualizing a language-related project with a novel deep learning application. Because of this language requirement and because my teammembers and I shared a mutual interest in music, we decided to focus on song lyrics. At first, we considered many topics like lyric generation and genre classification, but eventually settled on mood classificaiton after a thorough literature review.
Literature Review
Some of the influential papers we read along the way include
- tbd
Approach
This diagram represents, at a high-level, the key steps taken to reach our results:
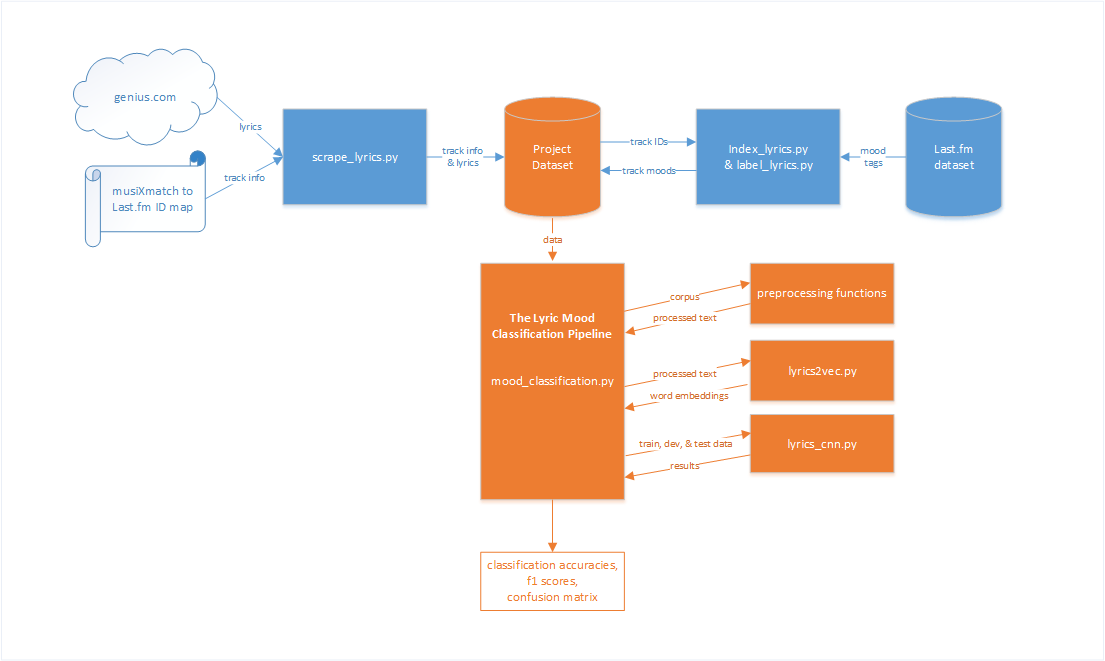
Steps:
- Attempt to download the song lyrics from genius.com for each track in the musiXmatch to Last.fm mapping file
- Index and label each song with its mood from the Last.fm dataset
- Import and preprocess all of the lyrics
- Generate word embeddings from the lyrics corpus
- Train and test the CNN model
Steps 3-5 are referred to as the Mood Classification Pipeline. More on that below.
Data
For our dataset, we made use of the Million Song Dataset (MSD).
The MSD is a dataset put together by some kind folks at Columbia that includes both audio and text-based musical data for over one-million tracks. I cannot comment on the audio data as we did not use it, but I did read some interesting papers that built models using both the audio and the lyrics as input.
It is made up of several companion datasets. The two we used were the
- musiXmatch dataset, the official lyrics collection of the Million Song Dataset.
- Last.fm dataset, the official song tag and song similarity dataset of the Million Song Dataset.
Of particular use was this giant text file mapping MSD IDs to musiXmatch IDs.
Unfortunately, we soon learned (after submititing our project proposal, of course) that the MSD’s lyrics are only available in a bag-of-words format. Bad news for us! We needed the lyrics in sequential form. And thus began the first big challenge of the project: acquiring the lyrics.
Downloading The Lyrics
After some hunting, we were able to locate a web API resource through which we could download lyrics: genius.com. Along the way, we learned that, although lyrics seem to be freely available on the internet, there are actually some strict copyrights governing how they can be used and distributed.
We quickly put together a web scraper and began pulling down the lyrics. That’s when we realized that at the rate of one song every 5 seconds, we were looking at 43 days of download time!
To speed things up, we parallelized the downloads. We set up 8 computers and separated the dataset into chunks. We were done in less than a week!
TODO:
- details on web api
- how many songs were attempted to be downloaded?
- how many lyrics were successfully downloaded?
Retrieving the Mood Labels
TODO: describe the moods
With our lyrics in hand, we were ready to attach our labels to begin model development and training. Unfortunately (again), getting the labels was not as easy as asking Last.fm, “hey what’s the mood for this song?”. No, we had to sort through user-entered tags.
These tags were entered by Last.fm users as free-form text, and they are provided in the Last.fm dataset with all of the horrors you’d expect: mispellings, irrelevance, etc. Thankfully, previous researchers did much trailblazing in this space and proved that, by searching through the tags for mood-related terms, you end up with plausible clusters of moods. I highly recommend giving this paper as a read if you’re interested in learning more. It is a great application of statistical and clustering technique in a domain with no right answer. You can find it here: Music Mood Representations From Social Tags.
We went through several iterations of matching tags to moods. Each method successfully labels songs, but each method also subsequently labels more songs (thus producing a larger dataset leading to a better classification accuracy). It is possible that each subsequent method returns more mislabeled songs than the previous, but we assume that the number mislabeled is neglible and did do some amount of manual screening to check.
- Exact mood matching
- Substring mood matching
- Expanded substring & synonym mood matching
Each method begins the same way: retrieve the track ID from the ID mapping file, and ask the Last.fm dataset for all tags associated with that track.
1. Exact Mood Matching
The first label retrieval method is the most straightforward: loop through each tag for a given track and check if it is an exact match for the mood.
Examples:
- Tag = “angry”, Mood = “angry”, Match? Yes.
- Tag = “fish”, Mood = “angry”, Match? No.
TODO: how many labeled songs did this return? TODO: bar chart showing distribution of labels TODO: make the examples prettier
2. Substring Mood Matching
Same as method 1, but this time check if a given tag contains the specified mood.
Examples:
- Tag = “what a sad song”, Mood = “sad”, Match? Yes.
- Tag = “saaad”, Mood = “sad”, Match? No.
- Tag = “How sadistic”, Mood = “sad”, Match? Yes (error).
3. Expanded Substring & Synonym Mood Matching
With this method, we enjoyed 2x the number of matched moods. It involves a bit more of a contrived approach to the problem. For a given mood, we check if a tag contains its exact match, a match of its common mispellings, and a match of any of its synonyms (synonyms retrieved from manual inspection of tags and an online thesaurus). We also, for each mood, have a list of “do not match” filters gathered through manual inspection of the dataset. If the mood matches but the tag contains one of these filters, we disregard the match.
Examples:
- Tag = “Makes me feel very down”, Mood = “sad” with synonym “down”, Match? Yes.
- Tag = “saaad”, Mood = “sad” with common mispelling “saaad”, Match? Yes.
- Tag = “Red hot chilli peppers”, Mood = “chill” with do-not-match filter “red hot chilli”, Match? No.
The Mood Classification Pipeline
Now that we have song lyrics and moods in hand (it is true what they say - these projects are mostly data preparing and cleaning!), we are ready to build some models.
Baseline Classifiers
To baseline our classifier, we use three different models:
- Most-common-case
- Naive Bayes
- Support Vector Machines (SVM)
Why baseline? Generating a baseline is a good idea for any project, especially projects involving neural networks. The idea is that neural networks are big and costly in terms of training time and resources (not to mention it is harder to get them to work!), so if a simpler classifier yields same or better results, save yourself the time and effort and go with the simpler one. But if you don’t baseline, then you’ll never know that a simpler approach might exist.
Lyric Preprocessing
TODO: describe
Word Embeddings
TODO: link to a good blog post on word embeddings TODO: add some pics of word embeddings
To generate our word embeddings, we use the popular word2vec model. Many projects use the pre-generated word2vec embeddings that are freely available to download, but we made the decision to generate our own with the belief that song lyrics typically use more colloquial, specialized speech than news articles.
It would have been interesting to experiment with the pre-generated embeddings to see how much, if at all, they impacted the results, but we did not have time (future work, perhaps?)
Convolutional Neural Network (CNN)
Our CNN architecture was based off of TODO: add Kim’s paper. After implementing the model in TensorFlow, we began experimenting with adjusting the hyperparameters.
TODO: link to some good intros on CNNs.
Results
TODO: elaborate
Code is open-sourced and available at https://github.com/workmanjack/w266-group-project_lyric-mood-classification
Final delivery was an academic paper that can be viewed here.